Tesseract OCRのPythonバインディング、tesserocrの使い方に関して。
この記事では過去記事で紹介しなかった、より高度な使用方法を紹介します。
目次#
環境#
- Ubuntu 18.04 LTS
- Python 3.6.5
- tesserocr 2.3.0
使用しているtesseractのバージョンは、tesseract 4.0.0-beta.1です。
github上で公開されている開発版では初期化に失敗する可能性があります。
詳細なインストール方法は過去記事を参照のこと。
テスト用の画像#
画像ファイルは以下のファイルを使用しています。




PyTessBaseAPI#
PyTessBaseAPIオブジェクトを初期化して使用します。基本的にTesseractのAPIと一対一対応した形式になります。
複数ファイルの一括処理#
from tesserocr import PyTessBaseAPI |
SetImageFile()の代わりにSetImage()メソッドを使用することでPillowやOpenCVなどの画像処理ライブラリと連携させることが可能です。
出力は以下に示しています。認識結果は良好。
日本語の文章は、漢字、カタカナ、ひらがなだけでなく、アルファベットや |
PyTessBaseAPIの初期化オプションは省略可能です。
その場合はデフォルトの言語である英語の言語別の辞書データが読み込まれ、ページセグメンテーションモードは自動判別となります。
PyTessBaseAPIの初期化オプションのリストを示します。
- path: tessdataディレクトリの親ディレクトリのパス(最後の文字が
/となっていなければならない) - lang: 言語名(
tessdataファイルの拡張子を除いた部分)を指定する - psm: ページセグメンテーションモード(0 - 13)
- init:
initメソッドを呼び出すか(もしFalseをセットした場合、初期化処理の完了後にinitメソッドを呼び出す必要あり) - oem: OCRエンジンモードを指定(0, 1, 2, 3)
ページセグメンテーションモード、OCRエンジンのモードはtesseractコマンドのオプションと同様です。
ページセグメンテーションモードの詳細ついてはWikiページまたはtesseractコマンドのヘルプメッセージを参照のこと。
ページセグメンテーションモードは整数で指定できますが、PSMモジュールをインポートすることで定義済みの定数を使用できます。
from tesserocr import PSM |
OCRエンジンモードのデフォルトは3でコンパイル時に指定されたエンジンです(通常は新しいLSTMベースの認識エンジン)。
従来の認識エンジンは0、新しい認識エンジンは1、両方を組み合わせ場合は2です。ただし、モード0および2を使用するには従来の認識エンジン用のファイルを含んだtraineddataファイルを用意する必要があります。
同様にOCRエンジンモードについてもOEMモジュールをインポートすることで定義済みの定数を使用できます。
from tesserocr import OEM |
イテレータの使用#
GetComponentImagesを使用することで、行や単語単位での認識結果の取り出しが可能です。
RILモジュールをインポートすることで定数として指定できます。
from tesserocr import RIL |
- ブロック(RIL.BLOCK)
- 段落(RIL.PARA)
- 行(RIL.TEXTLINE)
- 単語(RIL.WORD)
- 文字(RIL.SYMBOL)
なお、RILはResult Itelator Levelの略です。
認識結果が思わしくない場合、PyTessBaseAPIオブジェクトの初期化オプションを画像とRILの値に応じて変更して下さい。
文字を検出した領域の位置を取得できるので、Pillowという画像処理ライブラリをつかって矩形を描画してみます。
from tesserocr import PyTessBaseAPI |
出力は以下のようになります。
Found 9 word image components. |
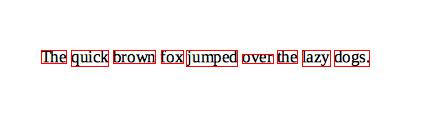
上記の場合、”over”という単語の認識に失敗しています。
Tesseract 4.xは余白にシビアなため、これはボックスの値を調整することで解決します。api.SetRectangle()の直前の位置で認識対象のボックスのy軸方向のサイズを調整するだけです。
Pillow、Tesseractともに座標系は左上が原点となります。したがって、box['y']の値を減少させると認識対象の領域が上方へ移動し、box['h']の値を増加させると下方に認識対象の領域が下方に伸長します。
api.SetRectangle(box['x'], box['y'], box['w'], box['h']) |
box['y'] -= 1 |
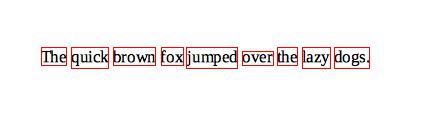
なお、行単位(RIL.TEXTLINE)で認識させた場合は問題なく認識します。

Found 1 word image components. |
OSD#
まず注意点。OSD(方向と文字種の判別)機能を利用する場合はosd.traineddataファイルが必要。また、言語もosd指定する必要がある。
2018年7月現在、提供されているosd.traineddataファイルは従来式の認識エンジン用のみ。したがってOCRエンジンモードもOEM.
DetectOS()#
Tesseractのバージョン3.0x系互換。DetectOS()を使用する方式。
from tesserocr import PyTessBaseAPI, PSM |
{'orientation': 0, 'oconfidence': 6.647193908691406, 'script': 18, 'sconfidence': 1.692307710647583} |
DetectOrientationScript()#
Tesseractのバージョン4以降ではDetectOrientationScript()メソッドを使用することでよりわかりやすい形式で出力を得ることができます。
from tesserocr import PyTessBaseAPI, PSM, OEM |
出力は以下のような人間に優しい形式になります。
{'orient_deg': 0, 'orient_conf': 6.647193908691406, 'script_name': 'Japanese', 'script_conf': 1.692307710647583} |
まとめ#
tesserocrはTesseractのC++ APIにほぼ対応しているので本家のWikiのドキュメントも参考になります。
hOCRおよびPDF形式で出力するAPIには対応していませんが、他の言語のTesseract OCRのライブラリにできることはほぼ全て対応しています。