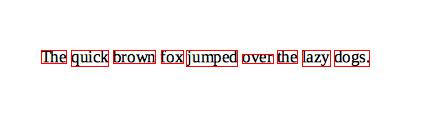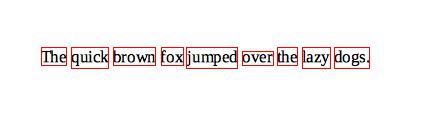TesseractError: (1, 'Tesseract Open Source OCR Engine v4.0.0-beta.4-20-ge9b4e with Leptonica Too few characters. Skipping this page Warning. Invalid resolution 0 dpi. Using 70 instead. Too few characters. Skipping this page Error during processing.')
改行が除去されて見づらいですがToo few characters. Skipping this pageというメッセージのとおり、文字数の不足が原因です。
tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) # The tools are returned in the recommended order of usage tool = tools[0]
lang = 'eng' txt = tool.image_to_string( Image.open('images/sample.jpg'), lang=lang, builder=pyocr.builders.TextBuilder() )
$ tesseract --help-oem OCR Engine modes: (see https://github.com/tesseract-ocr/tesseract/wiki#linux) 0 Legacy engine only. 1 Neural nets LSTM engine only. 2 Legacy + LSTM engines. 3 Default, based on what is available.
ページセグメンテーションモードの一覧表示。
$ tesseract --help-psm Page segmentation modes: 0 Orientation and script detection (OSD) only. 1 Automatic page segmentation with OSD. 2 Automatic page segmentation, but no OSD, or OCR. 3 Fully automatic page segmentation, but no OSD. (Default) 4 Assume a single column of text of variable sizes. 5 Assume a single uniform block of vertically aligned text. 6 Assume a single uniform block of text. 7 Treat the image as a single text line. 8 Treat the image as a single word. 9 Treat the image as a single word in a circle. 10 Treat the image as a single character. 11 Sparse text. Find as much text as possible inno particular order. 12 Sparse text with OSD. 13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
from tesserocr import PyTessBaseAPI from PIL import Image, ImageDraw
image = Image.open('./sample.jpg')
draw = ImageDraw.Draw(image)
with PyTessBaseAPI(lang='eng', psm=PSM.) as api: api.SetImage(image) boxes = api.GetComponentImages(RIL.WORD, True) print('Found {} word image components.'.format(len(boxes))) for i, (im, box, _, _) in enumerate(boxes): # im is a PIL image object # box is a dict with x, y, w and h keys api.SetRectangle(box['x'], box['y'], box['w'], box['h']) ocrResult = api.GetUTF8Text() conf = api.MeanTextConf() print( (u"Box[{0}]: x={x}, y={y}, w={w}, h={h}, confidence: {1}, text: {2}").format(i, conf, ocrResult, **box)) draw.rectangle([box['x'], box['y'], box['x']+box['w'], box['y']+box['h']],outline=(255, 0, 0))
image.save("sample_box.jpg")
出力は以下のようになります。
Found 9 word image components. Box[0]: x=41, y=50, w=25, h=13, confidence: 96, text: The
Do you want to proceed and uninstall pandoc (Y/N)?y Password: Deleted /usr/local/bin/pandoc Deleted /usr/local/bin/pandoc-citeproc Deleted /usr/local/share/man/man1/pandoc-citeproc.1 Deleted /usr/local/share/man/man1/pandoc.1 Forgot package 'net.johnmacfarlane.pandoc' on '/'. Pandoc has been successfully uninstalled.
npm WARN deprecated coffee-script@1.12.7: CoffeeScript on NPM has moved to "coffeescript" (no hyphen) + hexo-toc@1.1.0 added 67 packages from 72 contributors and audited 5845 packages in 17.872s found 17 vulnerabilities (4 low, 13 moderate) run `npm audit fix` to fix them, or `npm audit` for details
$ npm audit fix added 10 packages from 17 contributors and updated 1 package in 8.537s fixed 4 of 17 vulnerabilities in 5845 scanned packages 13 vulnerabilities required manual review and could not be updated